

- LLM 作为评判者:使用 LLM 评估跟踪作为类人判断的可扩展替代品(例如,毒性、幻觉、正确性)。支持两个不同的粒度级别:
- 运行级别:评估单个运行。
- 线程级别:评估线程中的所有跟踪。
- 自定义代码:直接在 LangSmith 中用 Python 编写评估器。通常用于验证数据的结构或统计属性。
当在线评估器在跟踪中的任何运行上运行时,跟踪将自动升级到延长数据保留。此升级将影响跟踪定价,但确保满足您的评估标准(通常是最有价值的分析)的跟踪被保留以供调查。
查看在线评估器
前往 Tracing Projects 选项卡并选择跟踪项目。要查看该项目的现有在线评估器,请单击 Evaluators 选项卡。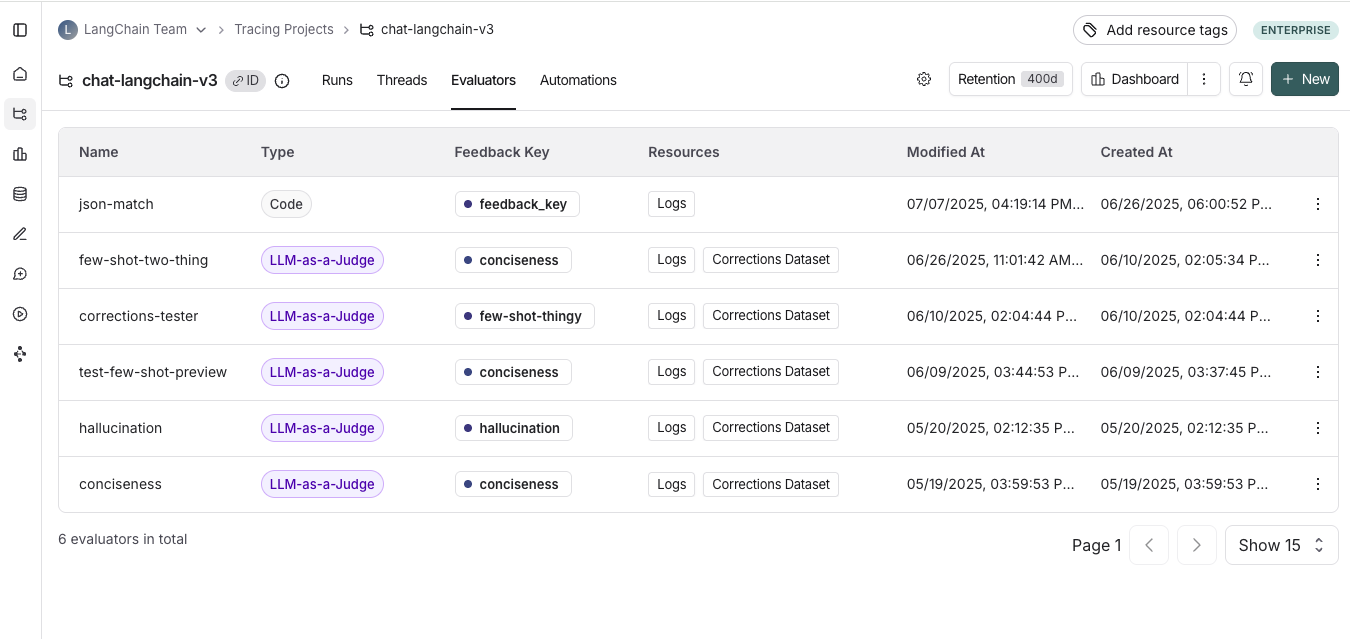
配置在线评估器
1. 导航到在线评估器
前往 Tracing Projects 选项卡并选择跟踪项目。单击跟踪项目页面右上角的 + New,然后单击 New Evaluator。选择您要配置的评估器。2. 命名评估器
3. 创建过滤器
例如,你可能希望根据以下条件应用特定评估器:- 用户留下反馈表示响应不满意的运行。
- 调用特定工具调用的运行。有关更多信息,请参阅过滤工具调用。
- 匹配特定元数据的运行(例如,如果你使用
plan_type记录跟踪,并且只想对企业客户的跟踪运行评估)。有关更多信息,请参阅向跟踪添加元数据。
4. (可选)配置采样率
配置采样率以控制触发自动化操作的过滤运行百分比。例如,为了控制成本,你可能希望设置过滤器,仅将评估器应用于 10% 的跟踪。为此,你需要将采样率设置为 0.1。5. (可选)将规则应用于过去的运行
通过切换 Apply to past runs 并输入”Backfill from”日期,将规则应用于过去的运行。这仅在创建规则时可能。注意:回填作为后台作业处理,因此你不会立即看到结果。 为了跟踪回填进度,你可以通过前往跟踪项目中的 Evaluators 选项卡并单击你创建的评估器的 Logs 按钮来查看评估器的日志。在线评估器日志类似于自动化规则日志。- 添加评估器名称
- 可选地过滤要应用评估器的运行或配置采样率。
- 选择 Apply Evaluator
6. 选择评估器类型
- 配置 LLM 作为评判者评估器
- 配置自定义代码评估器
配置 LLM 作为评判者在线评估器
查看本指南以配置 LLM 作为评判者评估器。配置自定义代码评估器
选择 custom code 评估器。编写评估函数
自定义代码评估器限制。允许的库:你可以导入所有标准库函数,以及以下公共包:网络访问:你无法从自定义代码评估器访问互联网。
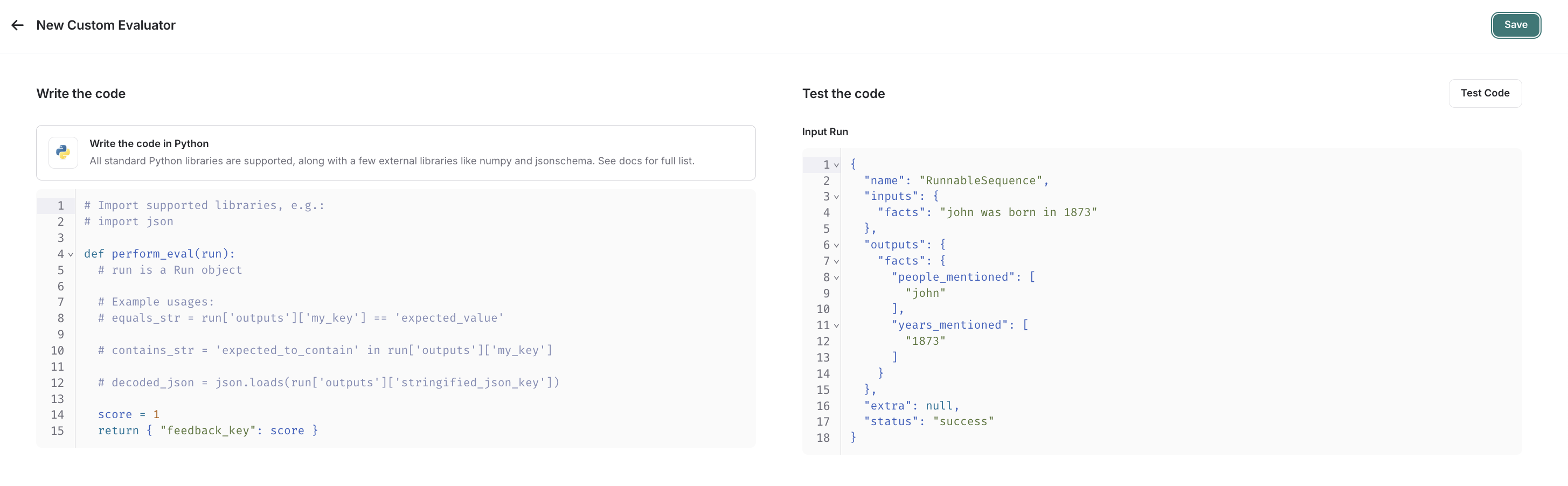 自定义代码评估器接受一个参数:
自定义代码评估器接受一个参数:
Run(参考)。这表示要评估的采样运行。
- 反馈字典:一个字典,其键是你想要返回的反馈类型,值是你为该反馈键给出的分数。例如,
{"correctness": 1, "silliness": 0}将在运行上创建两种类型的反馈,一个表示它是正确的,另一个表示它不愚蠢。
测试并保存评估函数
在保存之前,你可以通过单击 Test Code 在最近的运行上测试评估器函数,以确保代码正确执行。 一旦你保存,你的在线评估器将在新采样的运行(如果你选择了回填选项,也包括回填的运行)上运行。 如果你更喜欢视频教程,请查看 LangSmith 课程介绍中的在线评估视频。Video guide
配置多轮在线评估器
多轮在线评估器允许你评估人类和智能体之间的整个对话——而不仅仅是单个交换。它们测量线程中所有轮次的端到端交互质量。 你可以使用多轮评估来测量:- 语义意图:用户试图做什么。
- 语义结果:实际发生了什么,任务是否成功。
- 轨迹:对话如何展开,包括工具调用的轨迹。
Running multi-turn online evals will auto-upgrade each trace within a thread to extended data retention. This upgrade will impact trace pricing, but ensures that traces meeting your evaluation criteria (typically those most valuable for analysis) are preserved for investigation.
先决条件
- 你的跟踪项目必须使用线程。
- 线程中每个跟踪的顶级输入和输出必须具有包含消息列表的
messages键。我们支持 LangChain、OpenAI Chat Completions 和 Anthropic Messages 格式的消息。- 如果每个跟踪的顶级输入和输出仅包含对话中的最新消息,LangSmith 将自动将跨轮次的消息合并到线程中。
- 如果每个跟踪的顶级输入和输出包含完整的对话历史,LangSmith 将直接使用它。
如果你的跟踪不遵循上述格式,线程级评估器将无法工作。你需要更新向 LangSmith 跟踪的方式,以确保每个跟踪的顶级输入和输出包含
messages 列表。有关更多信息,请参阅故障排除部分。配置
- 导航到 Tracing Projects 选项卡并选择跟踪项目。
- 单击跟踪项目页面右上角的 + New > New Evaluator > Evaluate a multi-turn thread。
- 命名评估器。
- 应用过滤器或采样率。
使用过滤器或采样来控制评估器成本。例如,仅评估少于 N 轮的线程或对所有线程采样 10%。 - 配置空闲时间。
首次配置线程级评估器时,你将定义空闲时间——线程中最后一个跟踪之后到被认为完成并准备好进行评估的时间量。此值应反映应用程序中用户交互的预期长度。它适用于项目中的所有评估器。
-
配置模型。
选择要用于评估器的提供商和模型。线程往往会变长,因此你应该使用具有更高上下文窗口的模型,以避免遇到限制。例如,OpenAI 的 GPT-4.1 mini 或 Gemini 2.5 Flash 是不错的选择,因为它们都具有 1M+ token 上下文窗口。 -
配置 LLM 作为评判者提示。
定义你想要评估的内容。此提示将用于评估线程。你还可以配置将messages列表的哪些部分传递给评估器以控制其接收的内容:- 所有消息:发送完整的消息列表。
- 人类和 AI 对:仅发送用户和助手消息(不包括系统消息、工具调用等)。
- 第一个人类和最后一个 AI:仅发送第一个用户消息和最后一个助手回复。
-
设置反馈配置。
配置反馈键的名称、要收集的反馈格式,并可选择启用反馈的推理。
- 保存评估器。
限制
这些是多轮在线评估器的当前限制(可能会更改)。如果你遇到任何这些限制,请联系我们。- 运行必须少于一周:当线程变为空闲时,只有过去 7 天内的运行才有资格进行评估。
- 一次最多评估 500 个线程:如果你在五分钟内有超过 500 个线程标记为空闲,我们将自动采样超过 500 个。
- 每个工作区最多 10 个多轮在线评估器
故障排除
检查评估器的状态你可以通过前往跟踪项目中的 Evaluators 选项卡并单击你创建的评估器的 Logs 按钮来查看评估器上次运行的时间,以查看其运行历史。 检查发送给评估器的数据
通过前往跟踪项目中的 Evaluators 选项卡,单击你创建的评估器,然后单击 Evaluator traces 选项卡来检查发送给评估器的数据。 在此选项卡中,你可以看到传递给 LLM 作为评判者评估器的输入。如果你的消息未正确传递,你将在输入中看到空白值。如果你的消息未按照预期格式之一格式化,则可能发生这种情况。