from langchain_anthropic import ChatAnthropicfrom langchain_anthropic.middleware import AnthropicPromptCachingMiddlewarefrom langchain.agents import create_agentLONG_PROMPT = """Please be a helpful assistant.<Lots more context ...>"""agent = create_agent( model=ChatAnthropic(model="claude-sonnet-4-5-20250929"), system_prompt=LONG_PROMPT, middleware=[AnthropicPromptCachingMiddleware(ttl="5m")],)# cache storeagent.invoke({"messages": [HumanMessage("Hi, my name is Bob")]})# cache hit, system prompt is cachedagent.invoke({"messages": [HumanMessage("What's my name?")]})
from langchain.agents import create_agentfrom langchain.agents.middleware import ModelCallLimitMiddlewareagent = create_agent( model="gpt-4o", tools=[...], middleware=[ ModelCallLimitMiddleware( thread_limit=10, # Max 10 calls per thread (across runs) run_limit=5, # Max 5 calls per run (single invocation) exit_behavior="end", # Or "error" to raise exception ), ],)
Maximum tool calls across all runs in a thread (conversation). Persists across multiple invocations with the same thread ID. Requires a checkpointer to maintain state. None means no thread limit.
Maximum tool calls per single invocation (one user message → response cycle). Resets with each new user message. None means no run limit.Note: At least one of thread_limit or run_limit must be specified.
"continue" (default) - Block exceeded tool calls with error messages, let other tools and the model continue. The model decides when to end based on the error messages.
"error" - Raise a ToolCallLimitExceededError exception, stopping execution immediately
"end" - Stop execution immediately with a ToolMessage and AI message for the exceeded tool call. Only works when limiting a single tool; raises NotImplementedError if other tools have pending calls.
from langchain.agents import create_agentfrom langchain.agents.middleware import ModelFallbackMiddlewareagent = create_agent( model="gpt-4o", # Primary model tools=[...], middleware=[ ModelFallbackMiddleware( "gpt-4o-mini", # Try first on error "claude-3-5-sonnet-20241022", # Then this ), ],)
from langchain.agents import create_agentfrom langchain.agents.middleware import TodoListMiddlewarefrom langchain.messages import HumanMessageagent = create_agent( model="gpt-4o", tools=[...], middleware=[TodoListMiddleware()],)result = agent.invoke({"messages": [HumanMessage("Help me refactor my codebase")]})print(result["todos"]) # Array of todo items with status tracking
from langchain.agents import create_agentfrom langchain.agents.middleware import LLMToolSelectorMiddlewareagent = create_agent( model="gpt-4o", tools=[tool1, tool2, tool3, tool4, tool5, ...], # Many tools middleware=[ LLMToolSelectorMiddleware( model="gpt-4o-mini", # Use cheaper model for selection max_tools=3, # Limit to 3 most relevant tools always_include=["search"], # Always include certain tools ), ],)
from langchain.agents import create_agentfrom langchain.agents.middleware import LLMToolEmulatoragent = create_agent( model="gpt-4o", tools=[get_weather, search_database, send_email], middleware=[ # Emulate all tools by default LLMToolEmulator(), # Or emulate specific tools # LLMToolEmulator(tools=["get_weather", "search_database"]), # Or use a custom model for emulation # LLMToolEmulator(model="claude-sonnet-4-5-20250929"), ],)
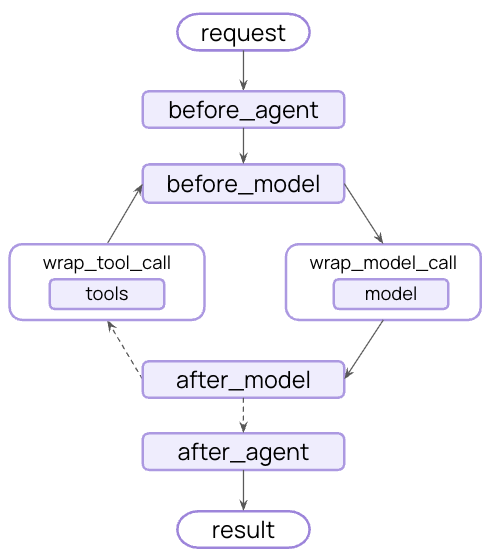
To exit early from middleware, return a dictionary with jump_to:
class EarlyExitMiddleware(AgentMiddleware): def before_model(self, state: AgentState, runtime) -> dict[str, Any] | None: # Check some condition if should_exit(state): return { "messages": [AIMessage("Exiting early due to condition.")], "jump_to": "end" } return None
Available jump targets:
"end": Jump to the end of the agent execution
"tools": Jump to the tools node
"model": Jump to the model node (or the first before_model hook)
Important: When jumping from before_model or after_model, jumping to "model" will cause all before_model middleware to run again.To enable jumping, decorate your hook with @hook_config(can_jump_to=[...]):
Select relevant tools at runtime to improve performance and accuracy.
Benefits:
Shorter prompts - Reduce complexity by exposing only relevant tools
Better accuracy - Models choose correctly from fewer options
Permission control - Dynamically filter tools based on user access
from langchain.agents import create_agentfrom langchain.agents.middleware import AgentMiddleware, ModelRequestfrom typing import Callableclass ToolSelectorMiddleware(AgentMiddleware): def wrap_model_call( self, request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: """Middleware to select relevant tools based on state/context.""" # Select a small, relevant subset of tools based on state/context relevant_tools = select_relevant_tools(request.state, request.runtime) request.tools = relevant_tools return handler(request)agent = create_agent( model="gpt-4o", tools=all_tools, # All available tools need to be registered upfront # Middleware can be used to select a smaller subset that's relevant for the given run. middleware=[ToolSelectorMiddleware()],)
Show Extended example: GitHub vs GitLab tool selection
from dataclasses import dataclassfrom typing import Literal, Callablefrom langchain.agents import create_agentfrom langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponsefrom langchain_core.tools import tool@tooldef github_create_issue(repo: str, title: str) -> dict: """Create an issue in a GitHub repository.""" return {"url": f"https://github.com/{repo}/issues/1", "title": title}@tooldef gitlab_create_issue(project: str, title: str) -> dict: """Create an issue in a GitLab project.""" return {"url": f"https://gitlab.com/{project}/-/issues/1", "title": title}all_tools = [github_create_issue, gitlab_create_issue]@dataclassclass Context: provider: Literal["github", "gitlab"]class ToolSelectorMiddleware(AgentMiddleware): def wrap_model_call( self, request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: """Select tools based on the VCS provider.""" provider = request.runtime.context.provider if provider == "gitlab": selected_tools = [t for t in request.tools if t.name == "gitlab_create_issue"] else: selected_tools = [t for t in request.tools if t.name == "github_create_issue"] request.tools = selected_tools return handler(request)agent = create_agent( model="gpt-4o", tools=all_tools, middleware=[ToolSelectorMiddleware()], context_schema=Context,)# Invoke with GitHub contextagent.invoke( { "messages": [{"role": "user", "content": "Open an issue titled 'Bug: where are the cats' in the repository `its-a-cats-game`"}] }, context=Context(provider="github"),)
Key points:
Register all tools upfront
Middleware selects the relevant subset per request