

概述
构建智能体(或任何 LLM 应用程序)的困难部分是使它们足够可靠。虽然它们可能适用于原型,但它们通常在实际用例中失败。为什么智能体会失败?
当智能体失败时,通常是因为智能体内部的 LLM 调用采取了错误的行动/没有做我们期望的事情。LLM 失败有两个原因之一:- 底层 LLM 能力不足
- “正确”的上下文没有传递给 LLM
智能体循环
典型的智能体循环包括两个主要步骤:- 模型调用 - 使用提示和可用工具调用 LLM,返回响应或执行工具的请求
- 工具执行 - 执行 LLM 请求的工具,返回工具结果
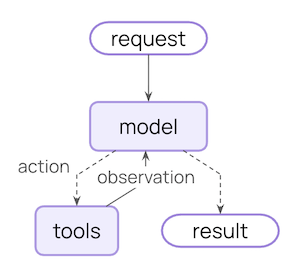
您可以控制什么
要构建可靠的智能体,您需要控制智能体循环的每个步骤以及步骤之间发生的事情。瞬态上下文
LLM 在单次调用中看到的内容。您可以修改消息、工具或提示,而不更改状态中保存的内容。
持久上下文
跨轮次保存在状态中的内容。生命周期钩子和工具写入永久修改此内容。
数据源
在整个过程中,您的智能体访问(读取/写入)不同的数据源:| 数据源 | 也称为 | 范围 | 示例 |
|---|---|---|---|
| 运行时上下文 | 静态配置 | 对话范围 | 用户 ID、API 密钥、数据库连接、权限、环境设置 |
| 状态 | 短期记忆 | 对话范围 | 当前消息、上传的文件、身份验证状态、工具结果 |
| 存储 | 长期记忆 | 跨对话 | 用户偏好、提取的见解、记忆、历史数据 |
工作原理
LangChain 中间件是使上下文工程对使用 LangChain 的开发人员实用的底层机制。 中间件允许您挂钩到智能体生命周期的任何步骤并:- 更新上下文
- 跳转到智能体生命周期中的不同步骤
模型上下文
控制每次模型调用的内容 - 指令、可用工具、使用的模型和输出格式。这些决策直接影响可靠性和成本。System Prompt
Base instructions from the developer to the LLM.
Messages
The full list of messages (conversation history) sent to the LLM.
Tools
Utilities the agent has access to to take actions.
Model
The actual model (including configuration) to be called.
Response Format
Schema specification for the model’s final response.
系统提示
系统提示设置 LLM 的行为和能力。不同的用户、上下文或对话阶段需要不同的指令。成功的智能体利用记忆、偏好和配置来为对话的当前状态提供正确的指令。- State
- Store
- Runtime Context
Access message count or conversation context from state:
消息
消息构成了发送给 LLM 的提示。 管理消息的内容至关重要,以确保 LLM 拥有正确的信息以做出良好的响应。- State
- Store
- Runtime Context
Inject uploaded file context from State when relevant to current query:
Transient vs Persistent Message Updates:The examples above use
wrap_model_call to make transient updates - modifying what messages are sent to the model for a single call without changing what’s saved in state.For persistent updates that modify state (like the summarization example in Life-cycle Context), use life-cycle hooks like before_model or after_model to permanently update the conversation history. See the middleware documentation for more details.工具
工具让模型与数据库、API 和外部系统交互。您如何定义和选择工具直接影响模型是否能够有效完成任务。定义工具
每个工具都需要清晰的名称、描述、参数名称和参数描述。这些不仅仅是元数据——它们指导模型关于何时以及如何使用工具的推理。Selecting tools
Not every tool is appropriate for every situation. Too many tools may overwhelm the model (overload context) and increase errors; too few limit capabilities. Dynamic tool selection adapts the available toolset based on authentication state, user permissions, feature flags, or conversation stage.- State
- Store
- Runtime Context
Enable advanced tools only after certain conversation milestones:
模型
不同的模型具有不同的优势、成本和上下文窗口。为当前任务选择正确的模型,这在智能体运行期间可能会发生变化。- State
- Store
- Runtime Context
Use different models based on conversation length from State:
响应格式
结构化输出将非结构化文本转换为经过验证的结构化数据。在提取特定字段或为下游系统返回数据时,自由格式文本是不够的。 工作原理: 当您提供模式作为响应格式时,模型的最终响应保证符合该模式。智能体运行模型/工具调用循环,直到模型完成工具调用,然后将最终响应强制转换为提供的格式。定义格式
模式定义指导模型。字段名称、类型和描述精确指定输出应遵循的格式。Selecting formats
Dynamic response format selection adapts schemas based on user preferences, conversation stage, or role—returning simple formats early and detailed formats as complexity increases.- State
- Store
- Runtime Context
Configure structured output based on conversation state:
工具上下文
工具的特殊之处在于它们既读取又写入上下文。 在最基本的情况下,当工具执行时,它接收 LLM 的请求参数并返回工具消息。工具执行其工作并产生结果。 工具还可以为模型获取重要信息,使其能够执行和完成任务。读取
大多数实际工具需要的不仅仅是 LLM 的参数。它们需要用于数据库查询的用户 ID、用于外部服务的 API 密钥或当前会话状态来做出决策。工具从状态、存储和运行时上下文读取以访问此信息。- State
- Store
- Runtime Context
Read from State to check current session information:
写入
工具结果可用于帮助智能体完成给定任务。工具既可以直接向模型返回结果,也可以更新智能体的记忆,以便为未来步骤提供重要的上下文。- State
- Store
Write to State to track session-specific information using Command:
生命周期上下文
控制核心智能体步骤之间发生的事情 - 拦截数据流以实现横切关注点,如摘要、护栏和日志记录。 正如您在模型上下文和工具上下文中看到的,中间件是使上下文工程实用的机制。中间件允许您挂接到智能体生命周期中的任何步骤,并:- 更新上下文 - 修改状态和存储以持久化更改、更新对话历史或保存见解
- 在生命周期中跳转 - 根据上下文移动到智能体循环中的不同步骤(例如,如果满足条件则跳过工具执行,使用修改后的上下文重复模型调用)
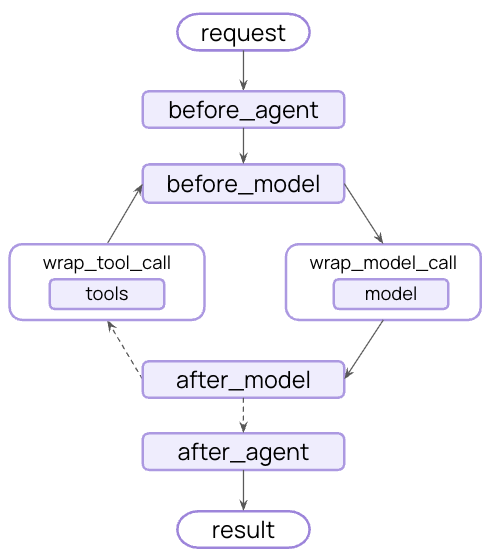
示例:摘要
最常见的生命周期模式之一是在对话历史过长时自动压缩它。与模型上下文中显示的临时消息修剪不同,摘要持久更新状态 - 永久地用摘要替换旧消息,该摘要会为所有未来的轮次保存。 LangChain offers built-in middleware for this:SummarizationMiddleware automatically:
- Summarizes older messages using a separate LLM call
- Replaces them with a summary message in State (permanently)
- Keeps recent messages intact for context
For a complete list of built-in middleware, available hooks, and how to create custom middleware, see the Middleware documentation.
最佳实践
- 从简单开始 - 从静态提示和工具开始,仅在需要时添加动态功能
- 增量测试 - 一次添加一个上下文工程功能
- 监控性能 - 跟踪模型调用、token 使用和延迟
- 使用内置中间件 - 利用
SummarizationMiddleware、LLMToolSelectorMiddleware等 - 记录您的上下文策略 - 清楚地说明正在传递什么上下文以及为什么
- 理解临时与持久:模型上下文更改是临时的(每次调用),而生命周期上下文更改会持久化到状态