

- 防止 PII 泄露
- 检测和阻止提示注入攻击
- 阻止不当或有害内容
- 强制执行业务规则和合规要求
- 验证输出质量和准确性
确定性护栏
使用基于规则的逻辑,如正则表达式模式、关键字匹配或显式检查。快速、可预测且成本效益高,但可能会错过细微的违规。
基于模型的护栏
使用 LLM 或分类器以语义理解评估内容。捕获规则遗漏的细微问题,但速度较慢且成本更高。
内置护栏
PII 检测
LangChain 提供用于检测和处理对话中的个人身份信息(PII)的内置中间件。此中间件可以检测常见的 PII 类型,如电子邮件、信用卡、IP 地址等。 PII 检测中间件对于具有合规要求的医疗保健和金融应用程序、需要清理日志的客户服务智能体以及处理敏感用户数据的任何应用程序都很有帮助。 PII 中间件支持多种处理检测到的 PII 的策略:| 策略 | 描述 | 示例 |
|---|---|---|
redact | 替换为 [REDACTED_TYPE] | [REDACTED_EMAIL] |
mask | 部分遮蔽(例如,最后 4 位数字) | ****-****-****-1234 |
hash | 替换为确定性哈希 | a8f5f167... |
block | 检测到时引发异常 | 抛出错误 |
Built-in PII types and configuration
Built-in PII types and configuration
Built-in PII types:
email- Email addressescredit_card- Credit card numbers (Luhn validated)ip- IP addressesmac_address- MAC addressesurl- URLs
| Parameter | Description | Default |
|---|---|---|
pii_type | Type of PII to detect (built-in or custom) | Required |
strategy | How to handle detected PII ("block", "redact", "mask", "hash") | "redact" |
detector | Custom detector function or regex pattern | None (uses built-in) |
apply_to_input | Check user messages before model call | True |
apply_to_output | Check AI messages after model call | False |
apply_to_tool_results | Check tool result messages after execution | False |
人在回路
LangChain 提供内置中间件,要求在执行敏感操作之前获得人工批准。这是高风险决策最有效的护栏之一。 Human-in-the-loop middleware is helpful for cases such as financial transactions and transfers, deleting or modifying production data, sending communications to external parties, and any operation with significant business impact.自定义护栏
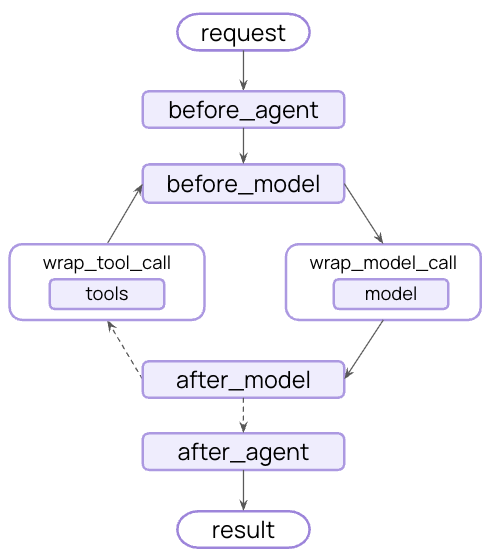
对于更复杂的护栏,您可以创建在智能体执行之前或之后运行的自定义中间件。这使您可以完全控制验证逻辑、内容过滤和安全检查。智能体前护栏
使用”智能体前”钩子在每次调用的开始时验证请求一次。这对于会话级检查很有用,例如身份验证、速率限制或在任何处理开始之前阻止不适当的请求。智能体后护栏
使用”智能体后”钩子在返回给用户之前验证最终输出一次。这对于基于模型的安全检查、质量验证或对完整智能体响应的最终合规性扫描很有用。组合多个护栏
您可以通过将多个护栏添加到中间件数组中来堆叠它们。它们按顺序执行,允许您构建分层保护:其他资源
- Middleware documentation - Complete guide to custom middleware
- Middleware API reference - Complete guide to custom middleware
- Human-in-the-loop - Add human review for sensitive operations
- Testing agents - Strategies for testing safety mechanisms