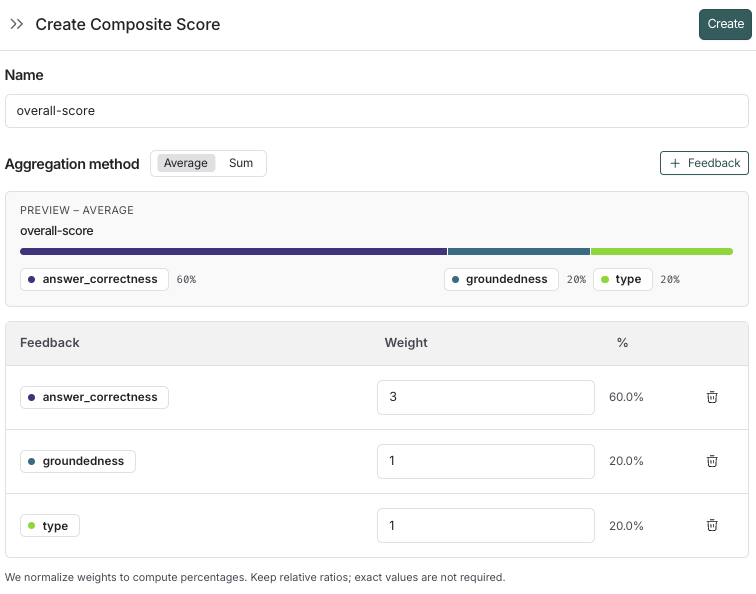
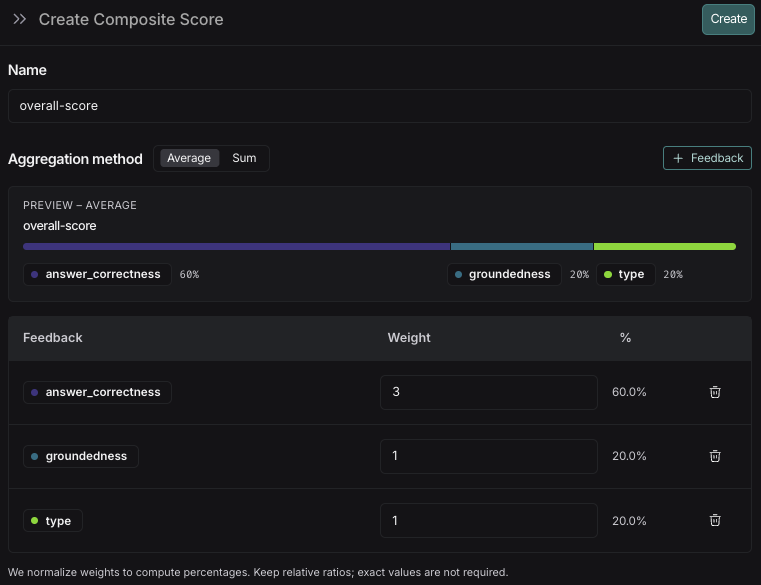
import os
from dotenv import load_dotenv
from openai import OpenAI
from langsmith import Client
from pydantic import BaseModel
import json
# Load environment variables from .env file
load_dotenv()
# Access environment variables
openai_api_key = os.getenv('OPENAI_API_KEY')
langsmith_api_key = os.getenv('LANGSMITH_API_KEY')
langsmith_project = os.getenv('LANGSMITH_PROJECT', 'default')
# Create a dataset. Only need to do this once.
client = Client()
oai_client = OpenAI()
examples = [
{
"inputs": {"blog_intro": "Today we’re excited to announce the general availability of LangSmith — our purpose-built infrastructure and management layer for deploying and scaling long-running, stateful agents. Since our beta last June, nearly 400 companies have used LangSmith to deploy their agents into production. Agent deployment is the next hard hurdle for shipping reliable agents, and LangSmith dramatically lowers this barrier with: 1-click deployment to go live in minutes, 30 API endpoints for designing custom user experiences that fit any interaction pattern, Horizontal scaling to handle bursty, long-running traffic, A persistence layer to support memory, conversational history, and async collaboration with human-in-the-loop or multi-agent workflows, Native Studio, the agent IDE, for easy debugging, visibility, and iteration "},
},
{
"inputs": {"blog_intro": "Klarna has reshaped global commerce with its consumer-centric, AI-powered payment and shopping solutions. With over 85 million active users and 2.5 million daily transactions on its platform, Klarna is a fintech leader that simplifies shopping while empowering consumers with smarter, more flexible financial solutions. Klarna’s flagship AI Assistant is revolutionizing the shopping and payments experience. Built on LangGraph and powered by LangSmith, the AI Assistant handles tasks ranging from customer payments, to refunds, to other payment escalations. With 2.5 million conversations to date, the AI Assistant is more than just a chatbot; it’s a transformative agent that performs the work equivalent of 700 full-time staff, delivering results quickly and improving company efficiency."},
},
]
dataset = client.create_dataset(dataset_name="Blog Intros")
client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
# Define a target function. In this case, we're using a simple function that generates a tweet from a blog intro.
def generate_tweet(inputs: dict) -> dict:
instructions = (
"Given the blog introduction, please generate a catchy yet professional tweet that can be used to promote the blog post on social media. Summarize the key point of the blog post in the tweet. Use emojis in a tasteful manner."
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": inputs["blog_intro"]},
]
result = oai_client.responses.create(
input=messages, model="gpt-5-nano"
)
return {"tweet": result.output_text}
# Define evaluators. In this case, we're using three evaluators: summary, formatting, and tone.
def summary(inputs: dict, outputs: dict) -> bool:
"""Judge whether the tweet is a good summary of the blog intro."""
instructions = "Given the following text and summary, determine if the summary is a good summary of the text."
class Response(BaseModel):
summary: bool
msg = f"Question: {inputs['blog_intro']}\nAnswer: {outputs['tweet']}"
response = oai_client.responses.parse(
model="gpt-5-nano",
input=[{"role": "system", "content": instructions,}, {"role": "user", "content": msg}],
text_format=Response
)
parsed_response = json.loads(response.output_text)
return parsed_response["summary"]
def formatting(inputs: dict, outputs: dict) -> bool:
"""Judge whether the tweet is formatted for easy human readability."""
instructions = "Given the following text, determine if it is formatted well so that a human can easily read it. Pay particular attention to spacing and punctuation."
class Response(BaseModel):
formatting: bool
msg = f"{outputs['tweet']}"
response = oai_client.responses.parse(
model="gpt-5-nano",
input=[{"role": "system", "content": instructions,}, {"role": "user", "content": msg}],
text_format=Response
)
parsed_response = json.loads(response.output_text)
return parsed_response["formatting"]
def tone(inputs: dict, outputs: dict) -> bool:
"""Judge whether the tweet's tone is informative, friendly, and engaging."""
instructions = "Given the following text, determine if the tweet is informative, yet friendly and engaging."
class Response(BaseModel):
tone: bool
msg = f"{outputs['tweet']}"
response = oai_client.responses.parse(
model="gpt-5-nano",
input=[{"role": "system", "content": instructions,}, {"role": "user", "content": msg}],
text_format=Response
)
parsed_response = json.loads(response.output_text)
return parsed_response["tone"]
# Calling evaluate() with the dataset, target function, and evaluators.
results = client.evaluate(
generate_tweet,
data=dataset.name,
evaluators=[summary, tone, formatting],
experiment_prefix="gpt-5-nano",
)
# Get the experiment name to be used in client.get_experiment_results() in the next section
experiment_name = results.experiment_name