from typing_extensions import Annotateddef add(left, right): """Can also import `add` from the `operator` built-in.""" return left + rightclass State(TypedDict): messages: Annotated[list[AnyMessage], add] extra_field: int
from langgraph.graph import STARTgraph = StateGraph(State).add_node(node).add_edge(START, "node").compile()result = graph.invoke({"messages": [HumanMessage("Hi")]})for message in result["messages"]: message.pretty_print()
================================ Human Message ================================Hi================================== Ai Message ==================================Hello!
input_message = {"role": "user", "content": "Hi"} result = graph.invoke({"messages": [input_message]})for message in result["messages"]: message.pretty_print()
================================ Human Message ================================Hi================================== Ai Message ==================================Hello!
This is a versatile representation of state for applications involving chat models. LangGraph includes a pre-built MessagesState for convenience, so that we can have:
from langgraph.graph import MessagesStateclass State(MessagesState): extra_field: int
When nodes execute in parallel, only one node can use Overwrite on the same state key in a given super-step. If multiple nodes attempt to overwrite the same key in the same super-step, an InvalidUpdateError will be raised.
from langgraph.graph import StateGraph, START, ENDfrom typing_extensions import TypedDict# Define the schema for the inputclass InputState(TypedDict): question: str# Define the schema for the outputclass OutputState(TypedDict): answer: str# Define the overall schema, combining both input and outputclass OverallState(InputState, OutputState): pass# Define the node that processes the input and generates an answerdef answer_node(state: InputState): # Example answer and an extra key return {"answer": "bye", "question": state["question"]}# Build the graph with input and output schemas specifiedbuilder = StateGraph(OverallState, input_schema=InputState, output_schema=OutputState)builder.add_node(answer_node) # Add the answer nodebuilder.add_edge(START, "answer_node") # Define the starting edgebuilder.add_edge("answer_node", END) # Define the ending edgegraph = builder.compile() # Compile the graph# Invoke the graph with an input and print the resultprint(graph.invoke({"question": "hi"}))
{'answer': 'bye'}
Notice that the output of invoke only includes the output schema.
from langgraph.graph import StateGraph, START, ENDfrom typing_extensions import TypedDict# The overall state of the graph (this is the public state shared across nodes)class OverallState(TypedDict): a: str# Output from node_1 contains private data that is not part of the overall stateclass Node1Output(TypedDict): private_data: str# The private data is only shared between node_1 and node_2def node_1(state: OverallState) -> Node1Output: output = {"private_data": "set by node_1"} print(f"Entered node `node_1`:\n\tInput: {state}.\n\tReturned: {output}") return output# Node 2 input only requests the private data available after node_1class Node2Input(TypedDict): private_data: strdef node_2(state: Node2Input) -> OverallState: output = {"a": "set by node_2"} print(f"Entered node `node_2`:\n\tInput: {state}.\n\tReturned: {output}") return output# Node 3 only has access to the overall state (no access to private data from node_1)def node_3(state: OverallState) -> OverallState: output = {"a": "set by node_3"} print(f"Entered node `node_3`:\n\tInput: {state}.\n\tReturned: {output}") return output# Connect nodes in a sequence# node_2 accepts private data from node_1, whereas# node_3 does not see the private data.builder = StateGraph(OverallState).add_sequence([node_1, node_2, node_3])builder.add_edge(START, "node_1")graph = builder.compile()# Invoke the graph with the initial stateresponse = graph.invoke( { "a": "set at start", })print()print(f"Output of graph invocation: {response}")
Entered node `node_1`: Input: {'a': 'set at start'}. Returned: {'private_data': 'set by node_1'}Entered node `node_2`: Input: {'private_data': 'set by node_1'}. Returned: {'a': 'set by node_2'}Entered node `node_3`: Input: {'a': 'set by node_2'}. Returned: {'a': 'set by node_3'}Output of graph invocation: {'a': 'set by node_3'}
Currently, the output of the graph will NOT be an instance of a pydantic model.
Run-time validation only occurs on inputs to the first node in the graph, not on subsequent nodes or outputs.
The validation error trace from pydantic does not show which node the error arises in.
Pydantic’s recursive validation can be slow. For performance-sensitive applications, you may want to consider using a dataclass instead.
from langgraph.graph import StateGraph, START, ENDfrom typing_extensions import TypedDictfrom pydantic import BaseModel# The overall state of the graph (this is the public state shared across nodes)class OverallState(BaseModel): a: strdef node(state: OverallState): return {"a": "goodbye"}# Build the state graphbuilder = StateGraph(OverallState)builder.add_node(node) # node_1 is the first nodebuilder.add_edge(START, "node") # Start the graph with node_1builder.add_edge("node", END) # End the graph after node_1graph = builder.compile()# Test the graph with a valid inputgraph.invoke({"a": "hello"})
Invoke the graph with an invalid input
try: graph.invoke({"a": 123}) # Should be a stringexcept Exception as e: print("An exception was raised because `a` is an integer rather than a string.") print(e)
An exception was raised because `a` is an integer rather than a string.1 validation error for OverallStatea Input should be a valid string [type=string_type, input_value=123, input_type=int] For further information visit https://errors.pydantic.dev/2.9/v/string_type
See below for additional features of Pydantic model state:
Serialization Behavior
When using Pydantic models as state schemas, it’s important to understand how serialization works, especially when:
Passing Pydantic objects as inputs
Receiving outputs from the graph
Working with nested Pydantic models
Let’s see these behaviors in action.
from langgraph.graph import StateGraph, START, ENDfrom pydantic import BaseModelclass NestedModel(BaseModel): value: strclass ComplexState(BaseModel): text: str count: int nested: NestedModeldef process_node(state: ComplexState): # Node receives a validated Pydantic object print(f"Input state type: {type(state)}") print(f"Nested type: {type(state.nested)}") # Return a dictionary update return {"text": state.text + " processed", "count": state.count + 1}# Build the graphbuilder = StateGraph(ComplexState)builder.add_node("process", process_node)builder.add_edge(START, "process")builder.add_edge("process", END)graph = builder.compile()# Create a Pydantic instance for inputinput_state = ComplexState(text="hello", count=0, nested=NestedModel(value="test"))print(f"Input object type: {type(input_state)}")# Invoke graph with a Pydantic instanceresult = graph.invoke(input_state)print(f"Output type: {type(result)}")print(f"Output content: {result}")# Convert back to Pydantic model if neededoutput_model = ComplexState(**result)print(f"Converted back to Pydantic: {type(output_model)}")
Runtime Type Coercion
Pydantic performs runtime type coercion for certain data types. This can be helpful but also lead to unexpected behavior if you’re not aware of it.
from langgraph.graph import StateGraph, START, ENDfrom pydantic import BaseModelclass CoercionExample(BaseModel): # Pydantic will coerce string numbers to integers number: int # Pydantic will parse string booleans to bool flag: booldef inspect_node(state: CoercionExample): print(f"number: {state.number} (type: {type(state.number)})") print(f"flag: {state.flag} (type: {type(state.flag)})") return {}builder = StateGraph(CoercionExample)builder.add_node("inspect", inspect_node)builder.add_edge(START, "inspect")builder.add_edge("inspect", END)graph = builder.compile()# Demonstrate coercion with string inputs that will be convertedresult = graph.invoke({"number": "42", "flag": "true"})# This would fail with a validation errortry: graph.invoke({"number": "not-a-number", "flag": "true"})except Exception as e: print(f"\nExpected validation error: {e}")
Working with Message Models
When working with LangChain message types in your state schema, there are important considerations for serialization. You should use AnyMessage (rather than BaseMessage) for proper serialization/deserialization when using message objects over the wire.
from langgraph.graph import StateGraph, START, ENDfrom pydantic import BaseModelfrom langchain.messages import HumanMessage, AIMessage, AnyMessagefrom typing import Listclass ChatState(BaseModel): messages: List[AnyMessage] context: strdef add_message(state: ChatState): return {"messages": state.messages + [AIMessage(content="Hello there!")]}builder = StateGraph(ChatState)builder.add_node("add_message", add_message)builder.add_edge(START, "add_message")builder.add_edge("add_message", END)graph = builder.compile()# Create input with a messageinitial_state = ChatState( messages=[HumanMessage(content="Hi")], context="Customer support chat")result = graph.invoke(initial_state)print(f"Output: {result}")# Convert back to Pydantic model to see message typesoutput_model = ChatState(**result)for i, msg in enumerate(output_model.messages): print(f"Message {i}: {type(msg).__name__} - {msg.content}")
================================ Human Message ================================hi================================== Ai Message ==================================Ciao! Come posso aiutarti oggi?
在许多用例中,您可能希望节点具有自定义重试策略,例如,如果您正在调用 API、查询数据库或调用 LLM 等。LangGraph 允许您向节点添加重试策略。To configure a retry policy, pass the retry_policy parameter to the add_node. The retry_policy parameter takes in a RetryPolicy named tuple object. Below we instantiate a RetryPolicy object with the default parameters and associate it with a node:
from langgraph.types import RetryPolicybuilder.add_node( "node_name", node_function, retry_policy=RetryPolicy(),)
By default, the retry_on parameter uses the default_retry_on function, which retries on any exception except for the following:
ValueError
TypeError
ArithmeticError
ImportError
LookupError
NameError
SyntaxError
RuntimeError
ReferenceError
StopIteration
StopAsyncIteration
OSError
In addition, for exceptions from popular http request libraries such as requests and httpx it only retries on 5xx status codes.
Extended example: customizing retry policies
Consider an example in which we are reading from a SQL database. Below we pass two different retry policies to nodes:
节点缓存在您希望避免重复操作的情况下很有用,例如在执行昂贵操作(在时间或成本方面)时。LangGraph 允许您向图中的节点添加个性化缓存策略。To configure a cache policy, pass the cache_policy parameter to the add_node function. In the following example, a CachePolicy object is instantiated with a time to live of 120 seconds and the default key_func generator. Then it is associated with a node:
from langgraph.types import CachePolicybuilder.add_node( "node_name", node_function, cache_policy=CachePolicy(ttl=120),)
Then, to enable node-level caching for a graph, set the cache argument when compiling the graph. The example below uses InMemoryCache to set up a graph with in-memory cache, but SqliteCache is also available.
from langgraph.cache.memory import InMemoryCachegraph = builder.compile(cache=InMemoryCache())
Why split application steps into a sequence with LangGraph?
LangGraph makes it easy to add an underlying persistence layer to your application.
This allows state to be checkpointed in between the execution of nodes, so your LangGraph nodes govern:
How we can “rewind” and branch-off executions using LangGraph’s time travel features
They also determine how execution steps are streamed, and how your application is visualized and debugged using Studio.Let’s demonstrate an end-to-end example. We will create a sequence of three steps:
Populate a value in a key of the state
Update the same value
Populate a different value
Let’s first define our state. This governs the schema of the graph, and can also specify how to apply updates. See this section for more detail.In our case, we will just keep track of two values:
from typing_extensions import TypedDictclass State(TypedDict): value_1: str value_2: int
Our nodes are just Python functions that read our graph’s state and make updates to it. The first argument to this function will always be the state:
Adding "A" to []Adding "B" to ['A']Adding "C" to ['A']Adding "D" to ['A', 'B', 'C']
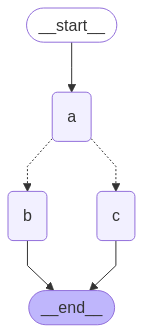
In the above example, nodes "b" and "c" are executed concurrently in the same superstep. Because they are in the same step, node "d" executes after both "b" and "c" are finished.Importantly, updates from a parallel superstep may not be ordered consistently. If you need a consistent, predetermined ordering of updates from a parallel superstep, you should write the outputs to a separate field in the state together with a value with which to order them.
Exception handling?
LangGraph executes nodes within supersteps, meaning that while parallel branches are executed in parallel, the entire superstep is transactional. If any of these branches raises an exception, none of the updates are applied to the state (the entire superstep errors).Importantly, when using a checkpointer, results from successful nodes within a superstep are saved, and don’t repeat when resumed.If you have error-prone (perhaps want to handle flakey API calls), LangGraph provides two ways to address this:
You can write regular python code within your node to catch and handle exceptions.
You can set a retry_policy to direct the graph to retry nodes that raise certain types of exceptions. Only failing branches are retried, so you needn’t worry about performing redundant work.
Together, these let you perform parallel execution and fully control exception handling.
Set max concurrency
You can control the maximum number of concurrent tasks by setting max_concurrency in the configuration when invoking the graph.
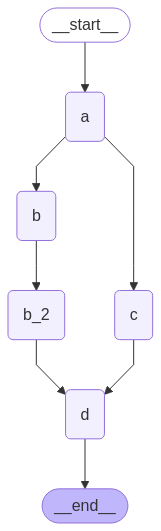
当您希望延迟节点的执行直到所有其他待处理任务完成时,延迟节点执行很有用。这在分支具有不同长度时特别相关,这在 map-reduce 流等工作流中很常见。The above example showed how to fan-out and fan-in when each path was only one step. But what if one branch had more than one step? Let’s add a node "b_2" in the "b" branch:
import operatorfrom typing import Annotated, Anyfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDclass State(TypedDict): # The operator.add reducer fn makes this append-only aggregate: Annotated[list, operator.add]def a(state: State): print(f'Adding "A" to {state["aggregate"]}') return {"aggregate": ["A"]}def b(state: State): print(f'Adding "B" to {state["aggregate"]}') return {"aggregate": ["B"]}def b_2(state: State): print(f'Adding "B_2" to {state["aggregate"]}') return {"aggregate": ["B_2"]}def c(state: State): print(f'Adding "C" to {state["aggregate"]}') return {"aggregate": ["C"]}def d(state: State): print(f'Adding "D" to {state["aggregate"]}') return {"aggregate": ["D"]}builder = StateGraph(State)builder.add_node(a)builder.add_node(b)builder.add_node(b_2)builder.add_node(c)builder.add_node(d, defer=True) builder.add_edge(START, "a")builder.add_edge("a", "b")builder.add_edge("a", "c")builder.add_edge("b", "b_2")builder.add_edge("b_2", "d")builder.add_edge("c", "d")builder.add_edge("d", END)graph = builder.compile()
from IPython.display import Image, displaydisplay(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke({"aggregate": []})
Adding "A" to []Adding "B" to ['A']Adding "C" to ['A']Adding "B_2" to ['A', 'B', 'C']Adding "D" to ['A', 'B', 'C', 'B_2']
如果您的扇出应该根据状态在运行时变化,您可以使用 add_conditional_edges 使用图状态选择一个或多个路径。请参阅下面的示例,其中节点 a 生成确定下一个节点的状态更新。
import operatorfrom typing import Annotated, Literal, Sequencefrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDclass State(TypedDict): aggregate: Annotated[list, operator.add] # Add a key to the state. We will set this key to determine # how we branch. which: strdef a(state: State): print(f'Adding "A" to {state["aggregate"]}') return {"aggregate": ["A"], "which": "c"} def b(state: State): print(f'Adding "B" to {state["aggregate"]}') return {"aggregate": ["B"]}def c(state: State): print(f'Adding "C" to {state["aggregate"]}') return {"aggregate": ["C"]}builder = StateGraph(State)builder.add_node(a)builder.add_node(b)builder.add_node(c)builder.add_edge(START, "a")builder.add_edge("b", END)builder.add_edge("c", END)def conditional_edge(state: State) -> Literal["b", "c"]: # Fill in arbitrary logic here that uses the state # to determine the next node return state["which"]builder.add_conditional_edges("a", conditional_edge) graph = builder.compile()
from IPython.display import Image, displaydisplay(Image(graph.get_graph().draw_mermaid_png()))
result = graph.invoke({"aggregate": []})print(result)
Adding "A" to []Adding "C" to ['A']{'aggregate': ['A', 'C'], 'which': 'c'}
Your conditional edges can route to multiple destination nodes. For example:
LangGraph 支持使用 Send API 进行 map-reduce 和其他高级分支模式。以下是如何使用它的示例:
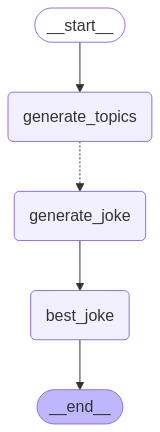
from langgraph.graph import StateGraph, START, ENDfrom langgraph.types import Sendfrom typing_extensions import TypedDict, Annotatedimport operatorclass OverallState(TypedDict): topic: str subjects: list[str] jokes: Annotated[list[str], operator.add] best_selected_joke: strdef generate_topics(state: OverallState): return {"subjects": ["lions", "elephants", "penguins"]}def generate_joke(state: OverallState): joke_map = { "lions": "Why don't lions like fast food? Because they can't catch it!", "elephants": "Why don't elephants use computers? They're afraid of the mouse!", "penguins": "Why don't penguins like talking to strangers at parties? Because they find it hard to break the ice." } return {"jokes": [joke_map[state["subject"]]]}def continue_to_jokes(state: OverallState): return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]def best_joke(state: OverallState): return {"best_selected_joke": "penguins"}builder = StateGraph(OverallState)builder.add_node("generate_topics", generate_topics)builder.add_node("generate_joke", generate_joke)builder.add_node("best_joke", best_joke)builder.add_edge(START, "generate_topics")builder.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])builder.add_edge("generate_joke", "best_joke")builder.add_edge("best_joke", END)graph = builder.compile()
from IPython.display import Image, displaydisplay(Image(graph.get_graph().draw_mermaid_png()))
# Call the graph: here we call it to generate a list of jokesfor step in graph.stream({"topic": "animals"}): print(step)
{'generate_topics': {'subjects': ['lions', 'elephants', 'penguins']}}{'generate_joke': {'jokes': ["Why don't lions like fast food? Because they can't catch it!"]}}{'generate_joke': {'jokes': ["Why don't elephants use computers? They're afraid of the mouse!"]}}{'generate_joke': {'jokes': ['Why don't penguins like talking to strangers at parties? Because they find it hard to break the ice.']}}{'best_joke': {'best_selected_joke': 'penguins'}}
创建带循环的图时,我们需要一种终止执行的机制。最常见的方法是通过添加条件边,一旦达到某个终止条件,该边就会路由到 END 节点。您还可以在调用或流式传输图时设置图递归限制。递归限制设置图在引发错误之前允许执行的超级步骤数。有关递归限制概念的更多信息,请参阅此处。让我们考虑一个带循环的简单图,以更好地理解这些机制的工作原理。
To return the last value of your state instead of receiving a recursion limit error, see the next section.
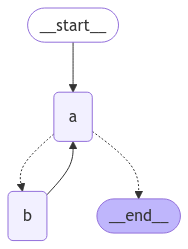
When creating a loop, you can include a conditional edge that specifies a termination condition:
builder = StateGraph(State)builder.add_node(a)builder.add_node(b)def route(state: State) -> Literal["b", END]: if termination_condition(state): return END else: return "b"builder.add_edge(START, "a")builder.add_conditional_edges("a", route)builder.add_edge("b", "a")graph = builder.compile()
To control the recursion limit, specify "recursionLimit" in the config. This will raise a GraphRecursionError, which you can catch and handle:
from langgraph.errors import GraphRecursionErrortry: graph.invoke(inputs, {"recursion_limit": 3})except GraphRecursionError: print("Recursion Error")
from IPython.display import Image, displaydisplay(Image(graph.get_graph().draw_mermaid_png()))
This architecture is similar to a ReAct agent in which node "a" is a tool-calling model, and node "b" represents the tools.In our route conditional edge, we specify that we should end after the "aggregate" list in the state passes a threshold length.Invoking the graph, we see that we alternate between nodes "a" and "b" before terminating once we reach the termination condition.
graph.invoke({"aggregate": []})
Node A sees []Node B sees ['A']Node A sees ['A', 'B']Node B sees ['A', 'B', 'A']Node A sees ['A', 'B', 'A', 'B']Node B sees ['A', 'B', 'A', 'B', 'A']Node A sees ['A', 'B', 'A', 'B', 'A', 'B']
Node A sees []Node B sees ['A']Node C sees ['A', 'B']Node D sees ['A', 'B']Node A sees ['A', 'B', 'C', 'D']Recursion Error
Extended example: return state on hitting recursion limit
Instead of raising GraphRecursionError, we can introduce a new key to the state that keeps track of the number of steps remaining until reaching the recursion limit. We can then use this key to determine if we should end the run.LangGraph implements a special RemainingSteps annotation. Under the hood, it creates a ManagedValue channel — a state channel that will exist for the duration of our graph run and no longer.
import operatorfrom typing import Annotated, Literalfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.managed.is_last_step import RemainingStepsclass State(TypedDict): aggregate: Annotated[list, operator.add] remaining_steps: RemainingStepsdef a(state: State): print(f'Node A sees {state["aggregate"]}') return {"aggregate": ["A"]}def b(state: State): print(f'Node B sees {state["aggregate"]}') return {"aggregate": ["B"]}# Define nodesbuilder = StateGraph(State)builder.add_node(a)builder.add_node(b)# Define edgesdef route(state: State) -> Literal["b", END]: if state["remaining_steps"] <= 2: return END else: return "b"builder.add_edge(START, "a")builder.add_conditional_edges("a", route)builder.add_edge("b", "a")graph = builder.compile()# Test it outresult = graph.invoke({"aggregate": []}, {"recursion_limit": 4})print(result)
Node A sees []Node B sees ['A']Node A sees ['A', 'B']{'aggregate': ['A', 'B', 'A']}
Extended example: loops with branches
To better understand how the recursion limit works, let’s consider a more complex example. Below we implement a loop, but one step fans out into two nodes:
import operatorfrom typing import Annotated, Literalfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDclass State(TypedDict): aggregate: Annotated[list, operator.add]def a(state: State): print(f'Node A sees {state["aggregate"]}') return {"aggregate": ["A"]}def b(state: State): print(f'Node B sees {state["aggregate"]}') return {"aggregate": ["B"]}def c(state: State): print(f'Node C sees {state["aggregate"]}') return {"aggregate": ["C"]}def d(state: State): print(f'Node D sees {state["aggregate"]}') return {"aggregate": ["D"]}# Define nodesbuilder = StateGraph(State)builder.add_node(a)builder.add_node(b)builder.add_node(c)builder.add_node(d)# Define edgesdef route(state: State) -> Literal["b", END]: if len(state["aggregate"]) < 7: return "b" else: return ENDbuilder.add_edge(START, "a")builder.add_conditional_edges("a", route)builder.add_edge("b", "c")builder.add_edge("b", "d")builder.add_edge(["c", "d"], "a")graph = builder.compile()
from IPython.display import Image, displaydisplay(Image(graph.get_graph().draw_mermaid_png()))
This graph looks complex, but can be conceptualized as loop of supersteps:
Node A
Node B
Nodes C and D
Node A
…
We have a loop of four supersteps, where nodes C and D are executed concurrently.Invoking the graph as before, we see that we complete two full “laps” before hitting the termination condition:
result = graph.invoke({"aggregate": []})
Node A sees []Node B sees ['A']Node D sees ['A', 'B']Node C sees ['A', 'B']Node A sees ['A', 'B', 'C', 'D']Node B sees ['A', 'B', 'C', 'D', 'A']Node D sees ['A', 'B', 'C', 'D', 'A', 'B']Node C sees ['A', 'B', 'C', 'D', 'A', 'B']Node A sees ['A', 'B', 'C', 'D', 'A', 'B', 'C', 'D']
However, if we set the recursion limit to four, we only complete one lap because each lap is four supersteps:
from langgraph.errors import GraphRecursionErrortry: result = graph.invoke({"aggregate": []}, {"recursion_limit": 4})except GraphRecursionError: print("Recursion Error")
Node A sees []Node B sees ['A']Node C sees ['A', 'B']Node D sees ['A', 'B']Node A sees ['A', 'B', 'C', 'D']Recursion Error
在并发运行 IO 密集型代码时(例如,向聊天模型提供商发出并发 API 请求),使用异步编程范式可以显著提高性能。要将图的 sync 实现转换为 async 实现,您需要:
更新 nodes 使用 async def 而不是 def。
更新内部代码以适当使用 await。
根据需要使用 .ainvoke 或 .astream 调用图。
Because many LangChain objects implement the Runnable Protocol which has async variants of all the sync methods it’s typically fairly quick to upgrade a sync graph to an async graph.See example below. To demonstrate async invocations of underlying LLMs, we will include a chat model:
from langchain.chat_models import init_chat_model# Follow the steps here to configure your credentials:# https://docs.aws.amazon.com/bedrock/latest/userguide/getting-started.htmlmodel = init_chat_model( "anthropic.claude-3-5-sonnet-20240620-v1:0", model_provider="bedrock_converse",)
def my_node(state: State) -> Command[Literal["my_other_node"]]: return Command( # state update update={"foo": "bar"}, # control flow goto="my_other_node" )
We show an end-to-end example below. Let’s create a simple graph with 3 nodes: A, B and C. We will first execute node A, and then decide whether to go to Node B or Node C next based on the output of node A.
import randomfrom typing_extensions import TypedDict, Literalfrom langgraph.graph import StateGraph, STARTfrom langgraph.types import Command# Define graph stateclass State(TypedDict): foo: str# Define the nodesdef node_a(state: State) -> Command[Literal["node_b", "node_c"]]: print("Called A") value = random.choice(["b", "c"]) # this is a replacement for a conditional edge function if value == "b": goto = "node_b" else: goto = "node_c" # 请注意 Command 如何允许您同时更新图状态并路由到下一个节点 return Command( # this is the state update update={"foo": value}, # this is a replacement for an edge goto=goto, )def node_b(state: State): print("Called B") return {"foo": state["foo"] + "b"}def node_c(state: State): print("Called C") return {"foo": state["foo"] + "c"}
We can now create the StateGraph with the above nodes. Notice that the graph doesn’t have conditional edges for routing! This is because control flow is defined with Command inside node_a.
You might have noticed that we used Command as a return type annotation, e.g. Command[Literal["node_b", "node_c"]]. This is necessary for the graph rendering and tells LangGraph that node_a can navigate to node_b and node_c.
from IPython.display import display, Imagedisplay(Image(graph.get_graph().draw_mermaid_png()))
If we run the graph multiple times, we’d see it take different paths (A -> B or A -> C) based on the random choice in node A.
def my_node(state: State) -> Command[Literal["my_other_node"]]: return Command( update={"foo": "bar"}, goto="other_subgraph", # where `other_subgraph` is a node in the parent graph graph=Command.PARENT )
一个常见的用例是从工具内部更新图状态。例如,在客户支持应用程序中,您可能希望在对话开始时根据客户的帐号或 ID 查找客户信息。要从工具更新图状态,您可以从工具返回 Command(update={"my_custom_key": "foo", "messages": [...]}):
@tooldef lookup_user_info(tool_call_id: Annotated[str, InjectedToolCallId], config: RunnableConfig): """Use this to look up user information to better assist them with their questions.""" user_info = get_user_info(config.get("configurable", {}).get("user_id")) return Command( update={ # update the state keys "user_info": user_info, # update the message history "messages": [ToolMessage("Successfully looked up user information", tool_call_id=tool_call_id)] } )
You MUST include messages (or any state key used for the message history) in Command.update when returning Command from a tool and the list of messages in messages MUST contain a ToolMessage. This is necessary for the resulting message history to be valid (LLM providers require AI messages with tool calls to be followed by the tool result messages).
If you are using tools that update state via Command, we recommend using prebuilt ToolNode which automatically handles tools returning Command objects and propagates them to the graph state. If you’re writing a custom node that calls tools, you would need to manually propagate Command objects returned by the tools as the update from the node.
Using Mermaid.ink API (does not require additional packages)
Using Mermaid + Pyppeteer (requires pip install pyppeteer)
Using graphviz (which requires pip install graphviz)
Using Mermaid.InkBy default, draw_mermaid_png() uses Mermaid.Ink’s API to generate the diagram.
from IPython.display import Image, displayfrom langchain_core.runnables.graph import CurveStyle, MermaidDrawMethod, NodeStylesdisplay(Image(app.get_graph().draw_mermaid_png()))
Using Mermaid + Pyppeteer
import nest_asyncionest_asyncio.apply() # Required for Jupyter Notebook to run async functionsdisplay( Image( app.get_graph().draw_mermaid_png( curve_style=CurveStyle.LINEAR, node_colors=NodeStyles(first="#ffdfba", last="#baffc9", default="#fad7de"), wrap_label_n_words=9, output_file_path=None, draw_method=MermaidDrawMethod.PYPPETEER, background_color="white", padding=10, ) ))
Using Graphviz
try: display(Image(app.get_graph().draw_png()))except ImportError: print( "You likely need to install dependencies for pygraphviz, see more here https://github.com/pygraphviz/pygraphviz/blob/main/INSTALL.txt" )


 In this case, our graph just executes a single node. Let’s proceed with a simple invocation:
In this case, our graph just executes a single node. Let’s proceed with a simple invocation:
 Let’s proceed with a simple invocation:请注意:
Let’s proceed with a simple invocation:请注意: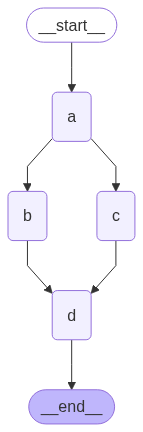 With the reducer, you can see that the values added in each node are accumulated.
With the reducer, you can see that the values added in each node are accumulated.
 This architecture is similar to a ReAct agent in which node
This architecture is similar to a ReAct agent in which node 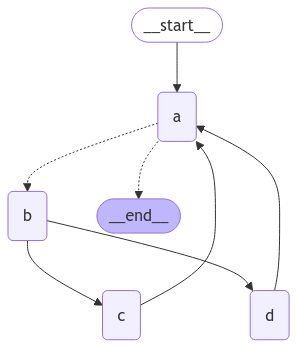 This graph looks complex, but can be conceptualized as loop of supersteps:However, if we set the recursion limit to four, we only complete one lap because each lap is four supersteps:
This graph looks complex, but can be conceptualized as loop of supersteps:However, if we set the recursion limit to four, we only complete one lap because each lap is four supersteps: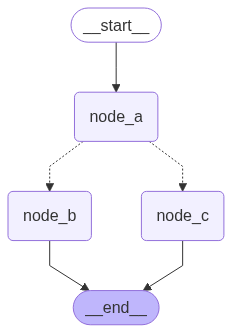 If we run the graph multiple times, we’d see it take different paths (A -> B or A -> C) based on the random choice in node A.
If we run the graph multiple times, we’d see it take different paths (A -> B or A -> C) based on the random choice in node A.
 Using Mermaid + Pyppeteer
Using Mermaid + Pyppeteer