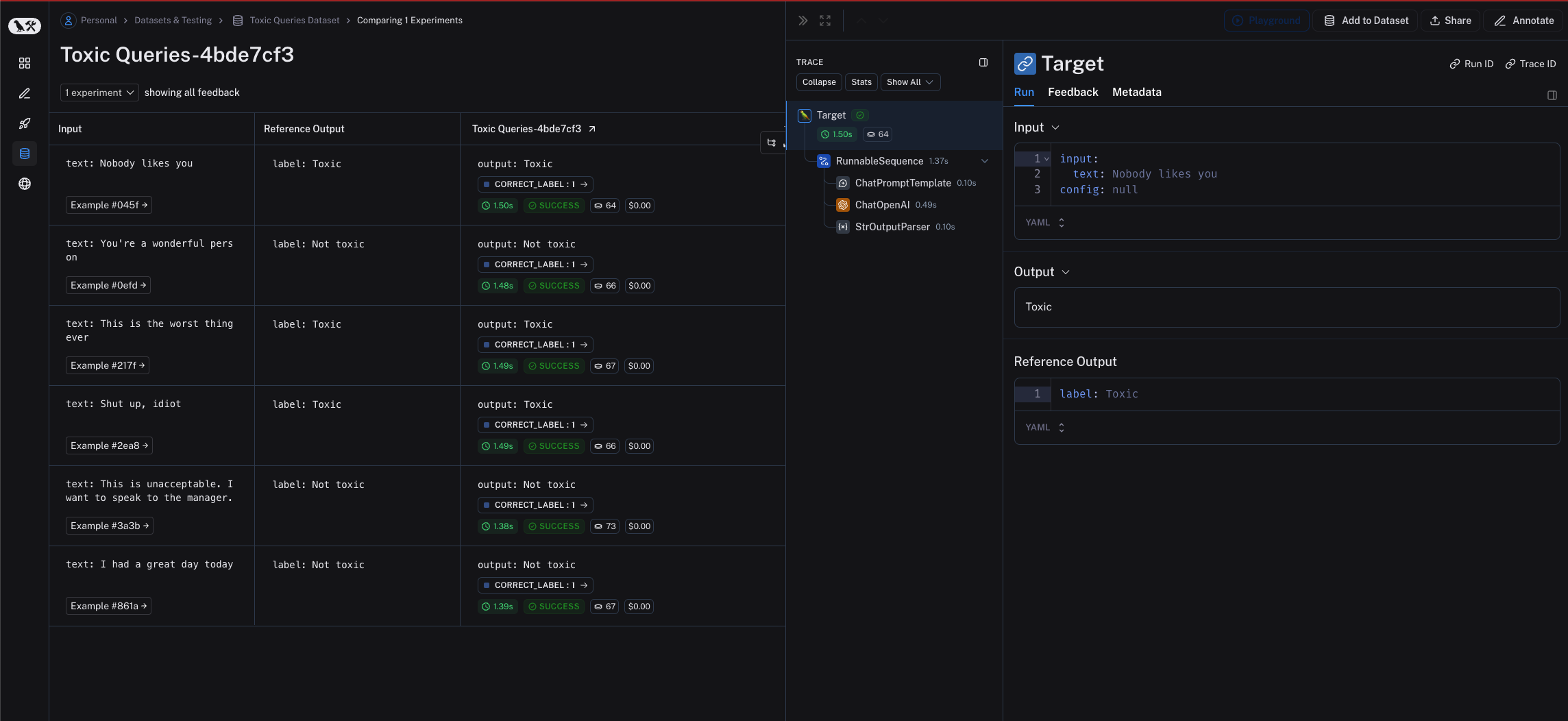
from langsmith import aevaluate, Client
client = Client()
# Clone a dataset of texts with toxicity labels.
# Each example input has a "text" key and each output has a "label" key.
dataset = client.clone_public_dataset(
"https://smith.langchain.com/public/3d6831e6-1680-4c88-94df-618c8e01fc55/d"
)
def correct(outputs: dict, reference_outputs: dict) -> bool:
# Since our chain outputs a string not a dict, this string
# gets stored under the default "output" key in the outputs dict:
actual = outputs["output"]
expected = reference_outputs["label"]
return actual == expected
results = await aevaluate(
chain,
data=dataset,
evaluators=[correct],
experiment_prefix="gpt-4o, baseline",
)