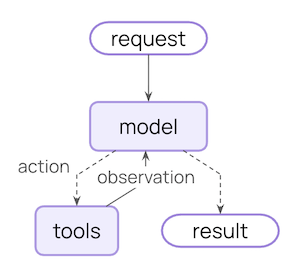
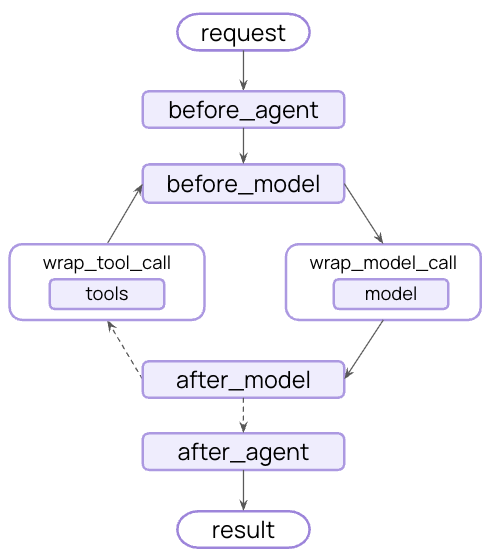
import { createAgent, HumanMessage, anthropicPromptCachingMiddleware } from "langchain";const LONG_PROMPT = `Please be a helpful assistant.<Lots more context ...>`;const agent = createAgent({ model: "claude-sonnet-4-5-20250929", prompt: LONG_PROMPT, middleware: [anthropicPromptCachingMiddleware({ ttl: "5m" })],});// cache storeawait agent.invoke({ messages: [new HumanMessage("Hi, my name is Bob")]});// cache hit, system prompt is cachedconst result = await agent.invoke({ messages: [new HumanMessage("What's my name?")]});
Maximum tool calls across all runs in a thread (conversation). Persists across multiple invocations with the same thread ID. Requires a checkpointer to maintain state. undefined means no thread limit.
Maximum tool calls per single invocation (one user message → response cycle). Resets with each new user message. undefined means no run limit.Note: At least one of threadLimit or runLimit must be specified.
"continue" (default) - Block exceeded tool calls with error messages, let other tools and the model continue. The model decides when to end based on the error messages.
"error" - Throw a ToolCallLimitExceededError exception, stopping execution immediately
"end" - Stop execution immediately with a ToolMessage and AI message for the exceeded tool call. Only works when limiting a single tool; throws error if other tools have pending calls.
import { createAgent, HumanMessage, todoListMiddleware } from "langchain";const agent = createAgent({ model: "gpt-4o", tools: [ /* ... */ ], middleware: [todoListMiddleware()] as const,});const result = await agent.invoke({ messages: [new HumanMessage("Help me refactor my codebase")],});console.log(result.todos); // Array of todo items with status tracking
Context properties are configuration values passed through the runnable config. Unlike state, context is read-only and typically used for configuration that doesn’t change during execution.Middleware can define context requirements that must be satisfied through the agent’s configuration:
To exit early from middleware, return a dictionary with jump_to:
Copy
import { createMiddleware, AIMessage } from "langchain";const earlyExitMiddleware = createMiddleware({ name: "EarlyExitMiddleware", beforeModel: (state) => { // Check some condition if (shouldExit(state)) { return { messages: [new AIMessage("Exiting early due to condition.")], jumpTo: "end", }; } return; },});
Available jump targets:
"end": Jump to the end of the agent execution
"tools": Jump to the tools node
"model": Jump to the model node (or the first before_model hook)
Important: When jumping from before_model or after_model, jumping to "model" will cause all before_model middleware to run again.To enable jumping, decorate your hook with @hook_config(can_jump_to=[...]):
Select relevant tools at runtime to improve performance and accuracy.
Benefits:
Shorter prompts - Reduce complexity by exposing only relevant tools
Better accuracy - Models choose correctly from fewer options
Permission control - Dynamically filter tools based on user access
Copy
import { createAgent, createMiddleware } from "langchain";const toolSelectorMiddleware = createMiddleware({ name: "ToolSelector", wrapModelCall: (request, handler) => { // Select a small, relevant subset of tools based on state/context const relevantTools = selectRelevantTools(request.state, request.runtime); const modifiedRequest = { ...request, tools: relevantTools }; return handler(modifiedRequest); },});const agent = createAgent({ model: "gpt-4o", tools: allTools, // All available tools need to be registered upfront // Middleware can be used to select a smaller subset that's relevant for the given run. middleware: [toolSelectorMiddleware],});
Show Extended example: GitHub vs GitLab tool selection
Copy
import * as z from "zod";import { createAgent, createMiddleware, tool, HumanMessage } from "langchain";const githubCreateIssue = tool( async ({ repo, title }) => ({ url: `https://github.com/${repo}/issues/1`, title, }), { name: "github_create_issue", description: "Create an issue in a GitHub repository", schema: z.object({ repo: z.string(), title: z.string() }), });const gitlabCreateIssue = tool( async ({ project, title }) => ({ url: `https://gitlab.com/${project}/-/issues/1`, title, }), { name: "gitlab_create_issue", description: "Create an issue in a GitLab project", schema: z.object({ project: z.string(), title: z.string() }), });const allTools = [githubCreateIssue, gitlabCreateIssue];const toolSelector = createMiddleware({ name: "toolSelector", contextSchema: z.object({ provider: z.enum(["github", "gitlab"]) }), wrapModelCall: (request, handler) => { const provider = request.runtime.context.provider; const toolName = provider === "gitlab" ? "gitlab_create_issue" : "github_create_issue"; const selectedTools = request.tools.filter((t) => t.name === toolName); const modifiedRequest = { ...request, tools: selectedTools }; return handler(modifiedRequest); },});const agent = createAgent({ model: "gpt-4o", tools: allTools, middleware: [toolSelector],});// Invoke with GitHub contextawait agent.invoke( { messages: [ new HumanMessage("Open an issue titled 'Bug: where are the cats' in the repository `its-a-cats-game`"), ], }, { context: { provider: "github" }, });
Key points:
Register all tools upfront
Middleware selects the relevant subset per request